As a guy who has his own deep learning library that aims to rival Tensorflow and PyTorch, the answer is: “chances are, no”.
Around this time last year, I was running a startup and as a side hustle, I was doing consulting work for any parties interested in machine learning. I get a lot of requests from businesses who want to empower their businesses with “AI”.
The results from any successful consults*Don't let terms like "consultancy" fool you - I spent 90% of the time getting rejections or me rejecting them. usually results in a deployment of ML systems that have little or nothing to do with deep learning.
Anatomy Of A Deep Learning System
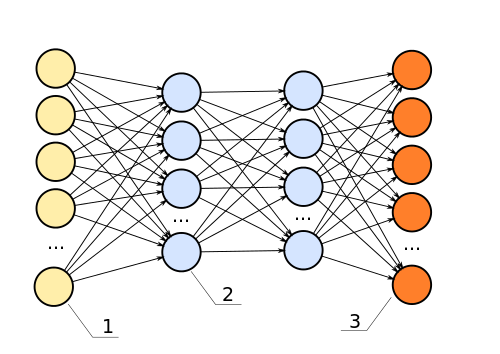
This is the typical representation of a neural network architecture, which I got from Wikipedia, released as public domain. A deep learning system is simply something similar to this, with many more layers. The functions between the layers may also be varied, but they are generally in this shape.
{kind=link}
Using this image as an archetypal deep learning system, there are two parts that are of interest to us. The last layer (in the picture above - the dark orange circles on the right), and the layers before it (the blues). What the deep layers do is to perform transformations to the input (yellow, left).
Hence one way of looking at deep learning systems (and one that not many would immediately agree with) is that the layers before the last are just feature engineering. The deep layers are simply there to automatically figure out what inputs to feed to the final layer for classification or regression.
With that in mind, this is the reason why most people I’ve given consultations to do not need deep learning: feature engineering is trivial for the input data. In fact, manual feature engineering would typically yield better results than putting it through multiple transformations.
A Quick Qualifying Questionnaire
To answer the question of whether you need deep learning, I’ve devised a questionnaire of sorts.
But first, Feature Engineering 101. The final goal of feature engineering is to construct a table of inputs. The columns represent the features, and each row represents a data point. This table (or more accurately, matrix) is then fed into an algorithm that performs some sort of regression, or classification.
So how do you do feature engineering? Here are some questions to get you started - if the answer is yes, move on to the next line:
- Can the problem be phrased in this way: “Given X, Y, Z, the result is A”?
- Can you describe a single data point in English (or whatever language you speak)?
- Now that the data can be described by words, are each feature easily extracted without needing statistical knowledge?
- Do some of the features form singularity?
- Are the features related to one another in non-linear ways?
- Can the data be cleaned easily or with simple statistical rules?
- Do you think there is a linear relationship between the outcome and your features?
If you answered yes to all the above, you don’t need deep learning. Manual feature engineering will get you superior results, and you have also done 50% of the feature engineering. The rest is just figuring out which features are useful - stuff you’d learn in any basic statistics class.
But also let’s take a look at some of the vaguer questions.
Question #2 is particularly interesting and worthy of a deeper look - We will use image classification as an example. A data point is an image. The data of the image cannot simply be described in English: you’d be describing the RGB values of every pixel. This part takes a bit of experience - it’s very easy and tempting to say “nope, can’t be described”. In my experience it’s usually because the notion of a “data point” is quite vague.
Question #4 is also another one that many people stumble on - This is a issue that many people fall into especially when working with dummy variables - it’s tempting to enumerate ALL the states and leave them each as 1 or 0.
When Do You Need Deep Learning?
As the developer of a deep learning library and occasional paid consultant for machine learning things, I have vested interest to say “all the time!”. But as a more responsible person, I’d say you only need deep learning in the following cases:
- The features of the data are not easily extracted (think images - the “old school” tools in the toolkit would be things like Hough transforms and Haar cascades)
- The features are highly correlated with one another in non-linear relationships
- The features cannot be created cleanly (for example: features that are compounds of raw features)
- The relationship between input and output are non-linear
- You don’t know what features are available
A benefit of not using deep learning is that the model is easily explained. This makes the last point above particularly interesting, especially in the context of latest research. With improved understanding of interpretability and tractability, we can instead make deep learning a step in the feature engineering process, to create a more streamlined program.
In my experience though, the last point can typically be attributed to what I perceive as a laziness to think.
Deep learning is not a panacea to all machine learning problems and it shouldn’t be. For that, something better will have to be invented - and not just a rebranding of deep learning into “differentiable computing”.
Conclusion and Notes
This post is a very light and brief overview of deep learning. There are clearly a number of nuances missed. But as far as a rough guideline for commercial use, I’d like to think this is a useful rough guide.
I’d like to thank Chen Chen for asking the initial set of questions that eventually led me to collect my answers into this blog post. Thanks to Ray Buhr and Rob Mooney for noticing and fixing a few errors.