I had fun at GopherConSG! It’s my third time at GopherConSG and after a few years of absence (thanks to COVID-19), it was sure good to see some old familiar faces like Valentine, Sau Sheong, Dave and Bill. This blog post is a retrospective on my GopherConSG 2023 talk: Man Bites Dog.
My GopherConSG talk was way too long. I had to trim down my talk from 1 hour 45 mins to 30 mins, and I feel like I missed a lot of the Go content. I learned quite a bit in the production of this talk.
Errata
If you were listening carefully to the talk (I’ll post the link when the video is out), you might have caught me slipping up in the early section where I accidentally spoke with two words with two syllables. Those were not supposed to happen.
There was a repeated sentence in the Is This Sentence Valid slides. The public version of the slides have the correct version.
More erratas will be added when the video is published.
The Goals of The Talk
When preparing any presentation, one has to consider the goals of the talk. What I wanted the audience to get out of the talk was the following:
- Understand the basic workings of a LLMs.
- Understand the fundamental limitations of LLMs.
- Introduce an alternative framework to think about and use LLMs.
- Show that Go is actually useful for the alternative frameworks on LLMs.
I like to think I managed to achieve the first and second points. I definitely didn’t achieve the latter two goals in the talk.
The main reason for this deficiency is that the list is in dependency order. Point 4 relies on Point 3, and point 3 relies on point 2 and point 1. Point 1 itself relies on some fundamentals that would need to be introduced first. The original dependency graph looks as follows:
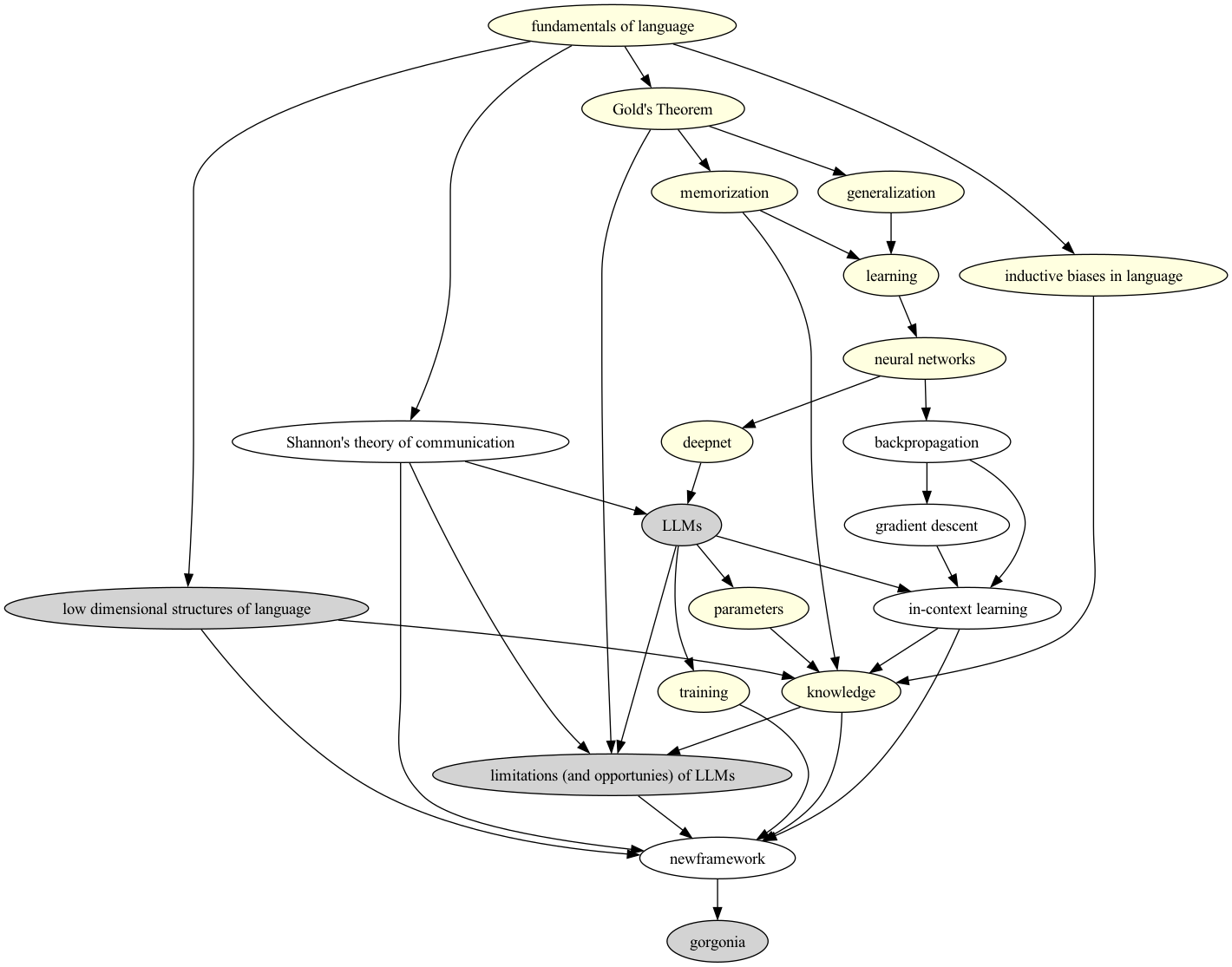
As you can see the original planned talk was way too large. Topics that were covered in the talk are the nodes with highlighted backgrounds. Light yellow topics are topics that I feel were relatively well covered in the talk. Grey topics are topics that I feel I didn’t cover well enough in the talk, owing either to time, or more content was cut out at the very last minutes.
The Making Of Man Bites Dog
This was a talk that I had wanted to give for some time. I originally submitted it to Strange Loop but didn’t make it. As such much of the frame of this talk was framed around the Strange Loop format. Even before Strange Loop, I had given a variation of this talk to some friends, as a private preview of what I was working on. In fact, the talk I ended up giving was cobbled from two talks I had previously prepared. One was about the limitations of LLMs and why I don’t think LLMs are the future of AI; and the other was about the connections between language and LLMs. Both of these talks originally featured some work that I was working on. My goal for GopherConSG was to incorporate some of these and talk about the refactoring work going into the Gorgonia family of libraries. I didn’t end up doing that due to running out of time.
Google Slides, RevealJS and Back
As always, my talks start in written form. I follow Barry Jay’s Three-Drafts Model:
- The first draft is to ensure everything is true. The audience is myself.
- The second draft is to ensure clarity.
- The third draft is to write with the final audience in mind.
After the talk is in done in its written form, I start on the slides.
I started with Google Slides, as the two talks I was cobbling this talk from had slides written in Google Slides. I then go to the part where I wanted to describe how machine learning was basically putting points on a manifold. I wrote a small (and truly ugly) animation using threejs. There was no way to embed arbitrary JavaScript and canvas animation on Google Slides. So I tried using RevealJS.
Manually writing slides using markdown seems like a good idea until you have to do it. I was working on the slides using RevealJS on the flight to Singapore. It wasn’t too long that I decided to give up due to sheer tediousness and reverted to Google Slides*Enabling offline editing was a lifesaver!.
Murrinpatha As An Introduction
In a very early version of the talk, I presented only Murrinpatha as an example. It was the reason why the talk was titled “Man Bits Dog”. This is due to the fact that in Murrinpatha, “man bites dog” and “dog bites man” (and in fact “bites dog man”, “bites man dog” “dog man bite” and “man dog bite”) may mean the same thing. The original talk was to point out the inherent biases in LLMs.
Unfortunately the group of friends I had presented this to all had linguistics as their educational background, so they were more hung up on the fact that Murrinpatha had free word order. Perhaps one of the more pertinent questions were “how did they [the Murrinpatha people] think?”. Needless to say, any discussions of LLMs and the inherent biases thereof ended up being undiscussed.
From Murrinpatha to Steeleish
So, using Murrinpatha alone drew attention away from the LLM bits of the presentation. I had to use something else. The goal was to introduce the audience to
- What a language is.
- The difficulties of representing the grammar for natural languages.
- The variation found in natural language.
- The inductive biases that have to be introduced in a language model.
Like most people, I have in my head, a bunch of talks I always revisit. One of them is Guy Steele’s Growing A Language talk. When I was observing a child acquiring language one day, I was suddenly reminded of the talk and thought that it would be a great way to achieve all those goals.
Easter Eggs
I usually include fun Easter eggs into my talks. These are usually conference and location specific. These are the intentional Easter eggs I included into this talk:
The Title Slide
A fun fact is that the title slide that I ended up presenting was made a couple of hours before my talk. The original title was a plain black slide. As I was walking to the conference venue, I walked past a newsstand. There was a pile of newspapers tied up in a rafia string. The newspapers were The Straits Times. And that was the inspiration for the title slide. Another fun fact is that I had most of the layout of the newspaper memorized correctly, with the exception of the typeface for the title. Somehow I had remembered the newspaper title to be a Fraktur type typeface. It was only after the conference that I picked up a newspaper and noticed that The Straits Times used a modern serif typeface.
I added to the background the How To Draw An Owl meme at the literal last minute. You see, I had been working on trimming my talk up to the point of having to give it. And at that point, it felt to me like a lot of my talk was going to end up being like the How To Draw An Owl meme. So I quickly inserted that into the background of my title slide.
The Lien Language
In the introduction part of the talk, I introduced the Lien language. “Lien” was of course the second syllable of the word “alien”. Because at that point I could only speak in one syllable words, I shortened it to “Lien”.
The words of the Lien language are derived from the demographics of Singapore. The main ethnic composition of Singapore are Chinese, Malay and Indian peoples. The main languages are Mandarin, Malay and Tamil respectively.
The word 🜣, “lén”, was derived from the Chinese character “
The word 🜟, pronounced “katj”, was derived from the Tamil word “
The word ꢯ, pronounced “jìng”, was derived from the Malay word “anjing”, which is pronounced “uhn-jing”, and means “dog”. The pronunciation was shortened to “jing” owing to the one-syllable rule.
The original idea was to have glyphs that are reminiscent of the original words - a pictogram of a human for 🜣, a Jawi-looking word for ꢯ and a Tamil-looking character for 🜟. I started with using conscripter to make my own fonts that have the glyphs I wanted. So I turned to font icons for these words, but it turned out much harder than expected to use images for glyphs, especially when there is so much to type. So I ended up looking around for strange looking unicode symbols. Many thanks to shapecatcher for providing the most useful service!
I tried not to use any glyphs from any known language, so that meant I had to use glyphs from the alchemy symbols block. I ended up with ꢯ because my fingers were misaligned on the keyboard on the flight*I was originally going for 0x1F711 (🜑) but typed 0xA8AF (ꢯ) when I was entering it into emacs, and it did look a bit like Tamil (if you only have a vague idea how Tamil writing looks like) … and time was running out so I stuck with it.
The Cutting Room Floor
One of the things that I cut out that I really liked was Shannon’s Mathematical Theory of Communication. The demonstration for the mathematical theory was one of those things that had to be demonstrated. In fact, the demonstration I had planned was indeed the same demonstration that Shannon did on his wife Mary: he’d pick out a sentence from a book and guess the next letter. From this he then proceeded to show that Mary’s brain contained a statistical model of the words of the English language*I wonder why that sounds so familiar..
Shannon took on the role of a principled engineer, so he declared that the role of a machine was to faithfully transmit information of a message, and has no role in understanding the semantics or pragmatics of a message. This theory underpins the designs of LLMs and neural models. Which is why it’s a little surprising that LLMs seem to be able to do more than syntax. Part of the talk deals with disentangling syntax and semantics - it ended up being the section where I talk about getting LLMs to generate the parallel postulate rather than the fifth postulate.
One other thing that I cut out was the section on in-context learning. Since 2017, I’ve tried to sneak in a mention or a picture of Godel in my talks. There was a slide which amounts to an image macro of Godel superimposed over Xzibit’s face with the text “Yo dawg I herd you like neural networks so I put a neural network in your neural network so you can predict while you predict”. Ultimately this was all cut because I had done this joke before.
Recalling Discussions
Despite advice to “trust the audience”, I think I am pretty glad that I did go through a large amount of background knowledge. During the afterparty, one guy came up to me and told me that despite having worked as a machine learning engineer for three years, it was my explanation of neural networks that cemented an understanding of what deep neural networks are. I think that was a highlight for me. Mind you, my explanation of neural networks was extremely rushed and required a fair amount of mathematical maturity. I wasn’t actually happy with it but that dude made my night.
I had also used the phrase “numberlike things” in my explanation of neural networks, and that phrase piqued the interests of more than one person. This resulted in a couple of pretty in-depth conversations about the nature of mathematics. The inclusion of the phrase was really more of a technical accuracy issue*i.e. floats are numberlike, they're not necessariliy numbers - at least in my mind. Nonetheless it did generate a bunch of most interesting discussions on neural networks built on geometric rotations and strings.
A couple of Singaporean attendees were surprised that I mentioned “Singlish has a grammar. You cannot put ’lah’ anywhere in a sentence”. One attendee told me later that he’d never thought of it that way. I stumbled when I tried to explain to Dave Cheney the role of the ‘-lah’ particle. This is strange because I’d grown up around people who use the ‘-lah’ particle freely and I would code switch to using Malaysian/Singaporean English when speaking to them. You’d think that I would be able to explain a daily phenomenon. Hilariously, Valentine Chua, the organizer of GopherConSG - a native Singaporean - stepped in and tried to explain the use of the particle and stumbled too. I guess observation yields a different language from use*What I mean is that it's often the case that linguists/grammarians observe a language and then write down the rules, while language users internalize it and as a result isn't necessarily aware of the rules. We can think of this as two different sets of languages that are somewhat intersecting in a large degree. I guess this is also where prescriptivism and descriptivism shows up.
A Longer Version
Most remarkably, two people came up to me after my talk and asked if I would be willing to record a longer version of this talk. I unfortunately was mindful enough only to get the contact details for one of them. The answer is I would, time permitting.
In fact, referring back to the original dependency graph above, I feel like there should be enough material for more than one YouTube video. So I may actually get round to doing it.
Lessons Learned
I started writing my talk about 3 weeks before GopherConSG. I should have started much earlier. When I gave the earlier version of my talk in March, the runtime ended up being over 2 hours, and even then I only covered Shannon’s theory of communication and in-context learning in 1 slide each.
I knew that this was a huge topic to cover. The old adage “know thy audience” keeps coming back to me. The audience at GopherConSG were mostly software developers, so this necessitated a large amount of background knowledge to be filled. The audience that would benefit from a shorter version of this talk would be an intersection of software engineers, programming language design enthusiasts, LLM enthusiasts, linguists and AI enthusiasts. There are no conferences for this specific intersection. So some background knowledge would have to be covered in any other conference.
What would I do different? I think I would have picked a different topic. Having said that, preparing for a talk or a paper almost always aids in thinking about the issues. In the preparation for this talk, I had found a bunch of issues around the new framework of thinking (which is why it ended up being cut, and not even talked about much, other than a brief mention as a “Bayesian ODE thing” in the talk).
Another thing would be to actually read out my prepared talk without slides while standing up. Had I done that earlier I would have a much better idea of how long the talk would take. Reading silently is heck a lot faster than reading out loud.